MTMineRのCART分析
フリーのテキストマイニングソフトMTMineRでCART分析をする方法を紹介します。
分析対象
今回、対象とするテキストデータは小説です。
CART分析で太宰治、芥川龍之介、森博嗣などの文章の特徴を分析します。
テキストマイニングツールのKH Coderでは品詞のBigramなどを出力できません。
CART分析のやり方
ここでは、形態素解析以降の手順を説明します。
CART分析でどのような文章の特徴で著者が分類されるか確認します。
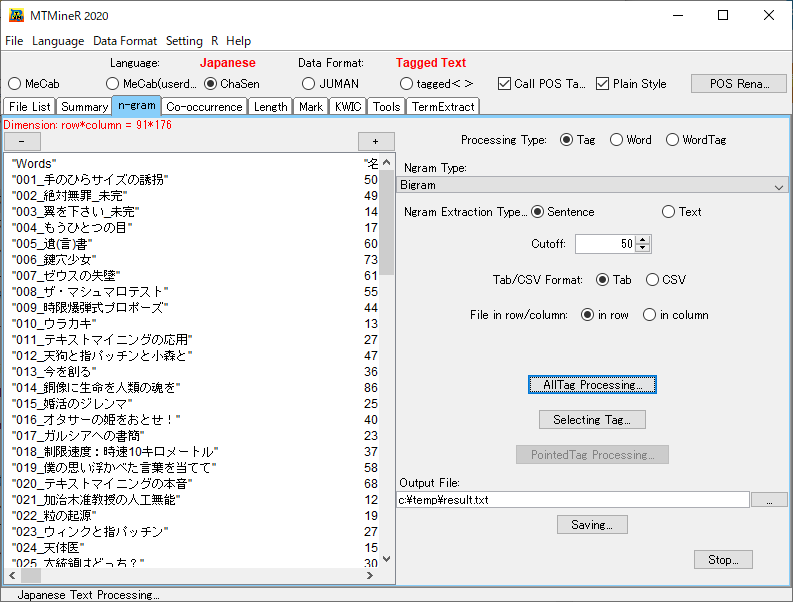
品詞のn-gram出力
<n-gram>というタブを選びます。下の画像は、参考画像です。こちらの画像は<AllTag Processing>を押した後に表示される画面です。

- 右半分の上部の<Processing Type>は、<Tag>を選択します。
- <Ngram Type>で<Bigram>を選択します。
- <Ngram Extraction Type>で<Sentence>を選択します。
- ここでは、<Cutoff>は50に設定しています。
- <Tab/CSV Format>や<File in row/column>はデフォルトから変更しません。
- 設定が完了したら<AllTag Processing>をクリックします。
名詞や動詞、副詞など、品詞を出力します。
これは品詞の組み合わせを意味します。この場合、名詞+助詞、助詞+動詞などです。
句点で区切られた文を一文とします。
出力形式を変えるだけなので、結果に影響はありません。
R実行画面で相対頻度に変換
R実行画面を立ち上げたら、まず、データ相対頻度に変換します。
下の画像は参考画面です。

- メニューから<R>をクリックし、<Process Outputs In This Tab>を選択します。
- Run Rの画面の<Command>が<Proportion in Each Row>となっていることを確認し、中央下の<Processing>を押します。
- Run R画面上部の<Select Data>から、データの名前を選択します。
- なお、Processing Sucessの画面は<OK>を押し、閉じます。
Set Data Nameで好きな名前を入力します。temp、のままでも大丈夫です。
<OK>を押すと、三つの画面が立ち上がります。
これで、行(Row)の総和を基準とした相対頻度に変えることができます。
この手順の1番目で、Data Nameをtempにしていれば、名前はtemp.traになっているはずです。
R実行画面でグルーピングする
<Spervised>のタブで<Grouping>を選び、作家を予め分類します。
実行画面は下の画像の通りです。この状態で<OK>を押すと、名前を変更していない場合は、temp.tra.groupedというデータが作られます。

- <Supervised>のタブで<Grouping>を選びます。
- <Enter the groups>を<Yes>にします。
- <Please enter groups separating by commans>の下にあるボックスにひとつのデータとする番号を入力します。
- <Please enter the name of groups separating by commans>の下にあるボックスに、データの名前を付けます。
- 画面下の<OK>を押します。
例えば、太宰治の作品が、49番目から74番目にあれば、<49:74>と入力します。
番号は、上部にあるボックスの一番左の数字です。
R実行画面でCART分析を実行する
<Spervised>のタブで<CART>を選び、決定木を描きます。
実行画面は下の画像の通りです。このような状態で<OK>を押すと、決定木が出力されます。

- <Spervised>のタブで<CART>を選びます。
- <Vriables>の下にあるボックスから<Denpendent variables:>の下にボックスに移します。
- <Vriables>の下にあるボックスから<Indenpendent variables:>の下にボックスに移します。
- <Subset>の下にあるボックスから<Training data:>の下にボックスに移します。
- Testingを実行する場合は<Testing data>にデータを移動します。
- 画面下の<OK>を押します。
まず<type>を選択し、一番上の丸い青い右向きの矢印を押すと、左から右へ移動します。
上から二番目の丸い青い右向きの矢印を押すと、全てのデータが左から右へ移動します。
これも、上から三番目の丸い青い右向きの矢印を押すと、左から右へ移動します。
これは教師データを選択しています。
また、<Output>の<Testing>にチェックを入れる必要があります。
結果
下図のような決定木が出力されます。
私の作品と太宰治の作品の特徴は動詞と助詞の組み合わせの多さが違うということがわかります。
ただし、いくつかのデータをTestingしてみると、その精度は57%程度となります。

参考文献
・テキストマイニングによる筆者識別の正確性ならびに判定手続きの標準化
2.5文体的特徴で、品詞のbigramの記述があります。筆者識別力が高い文章の特徴として挙げられています。また、この論文はMTMineRを使って分析してます。