MTMineRのSVM
MTMineRでサポートベクターマシン(SVM)を実行する方法を紹介します。
対象
今回、対象とするテキストデータは小説です。
太宰治、芥川龍之介、森博嗣、素人の作品を分析します。
テキストマイニングツールのKH Coderは、品詞のBigramなどを出力できないため、MTMineRでないとできない分析です。
SVMのやり方
ここでは、形態素解析以降の手順を説明します。
いくつかの小説を教師データとして学習させ、テストデータが誰の作品であるか判別させます。
①品詞のn-gram出力
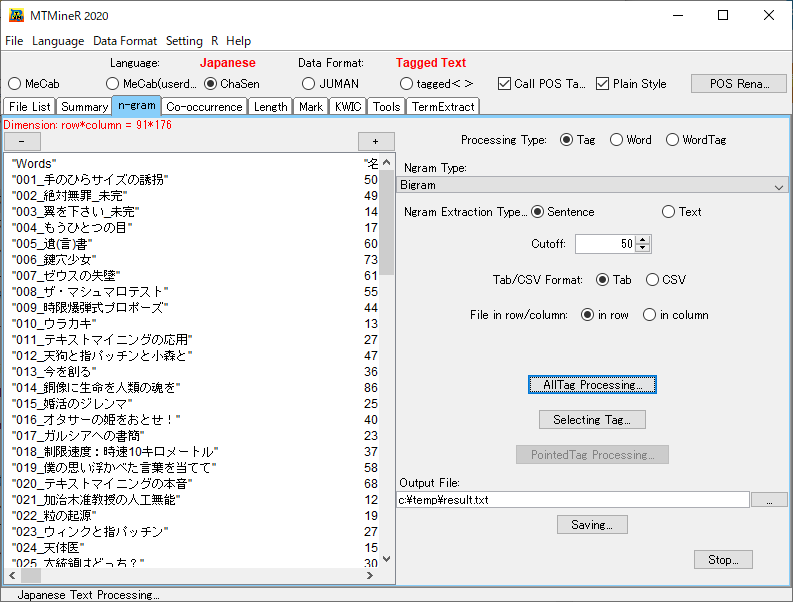
品詞の組み合わせを出力する手順を説明します。下記の手順と画像を参考にして下さい。
- <Processing Type>で<Tag>を選択
- <Ngram Type>で<Bigram>を選択
- <Ngram Extraction Type>で<Sentence>を選択
- <Cutoff>を50に設定
これで、名詞など、品詞のタグを出力します。
バイグラムとは、品詞の組み合わせのことです。
ここで、句点で区切られた文を一文とします。
設定が完了したら<AllTag Processing>をクリックします。

②R実行画面で相対頻度に変換
R実行画面を立ち上げ、データを相対頻度に変換します。
- メニューから<R>をクリックし<Process Outputs In This Tab>を選択
- <OK>を押し三つの画面が立ち上げる
- Run Rの画面の<Command>を<Proportion in Each Row>に設定
- 画面中央下の<Processing>を押す
- Run R画面上部の<Select Data>から、データの名前を選択
- Processing Sucessの画面は<OK>を押し閉じる
Set Data Nameで好きな名前を入力できますが、とりあえず、temp、で大丈夫です。
行(Row)の総和を基準とした相対頻度となります。
これで、相対頻度に変えることができます。
Data Nameがtempの場合、名前はtemp.traです。

③R実行画面でグルーピングする
作家を予めグループに分け、temp.tra.groupedというデータを作ります。
手順は下記の通りです。
- <Supervised>のタブで<Grouping>を選択
- <Enter the groups>を<Yes>に設定
- <Please enter groups separating by commans>の下にあるボックスに番号を入力
- <Please enter the name of groups separating by commans>の下にあるボックスにデータの名前を入力
- 画面下の<OK>を押す
太宰治の作品が、上部のボックスの中で、49番目から74番目にあれば、<49:74>と入力します。

④R実行画面でSVMを実行する
サポータベクターマシンを実行します。結果はOUTPUTの画面に表示されます。
- <Spervised>のタブで<SVM>を選択
- <Vriables>の下にあるボックスから<type>を選択
- 一番上の丸い青い右向きの矢印を押し<Denpendent variables:>の下のボックスへ移動
- 上から二番目の丸い青い右向きの矢印を押し全てのデータを移動
- 上から三番目の丸い青い右向きの矢印を押し全てのデータを移動
- <Training data:>からいくつかデータ選択
- 上から三番目の丸い青い左向きの矢印を押しデータを移動
- 上から四番目の丸い青い右向きの矢印を押しデータを移動
- <Output>の<Testing>にチェックを入れる
- 画面下の<OK>を押します。
ここでは全データをSVMに使用します。
<Vriables>の下から<Indenpendent variables:>に移動しているはずです。
全データを学習データにします。
<Subset>の下から<Training data:>にデータが移動しているはずです。
Ctrlを押しながら左クリックで複数選択ができます。
<Training data:>の下から<Subset>にデータが戻ります。
<Subset>の下から<Testing data:>にデータが移動します。

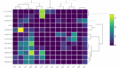
SVMの結果
下図のような結果が出力されます。
結果をみると、素人(マゼンタ)の作品が識別できています。精度は100%です。

参考文献
・テキストマイニングによる筆者識別の正確性ならびに判定手続きの標準化
2.5文体的特徴で、品詞のbigramの記述があります。筆者識別力が高い文章の特徴として挙げられています。また、この論文はMTMineRを使って分析してます。
・ランダムフォレスト法による文章の書き手の同定
タイトルはランダムフォレストですが、サポートベクターマシンも使用しています。書き手の同定について、その有効性をk近傍法などの手法と比較しています。