MTMineRのクラスター分析
MTMineRで階層的クラスター分析をする方法を紹介します。
分析対象
今回、対象とするテキストデータは小説です。太宰治と芥川龍之介、森博嗣などの作品をクラスター分析で分類します。
テキストマイニングツールのKH Coderでは、品詞のBigramなどを出力できないため、MTMineRでないとできない分析です。
やり方
形態素解析は完了している状態から、進めます。階層的クラスター分析で、太宰や芥川などの著者を分類できるか確認してみます。
品詞のBigramを出力する
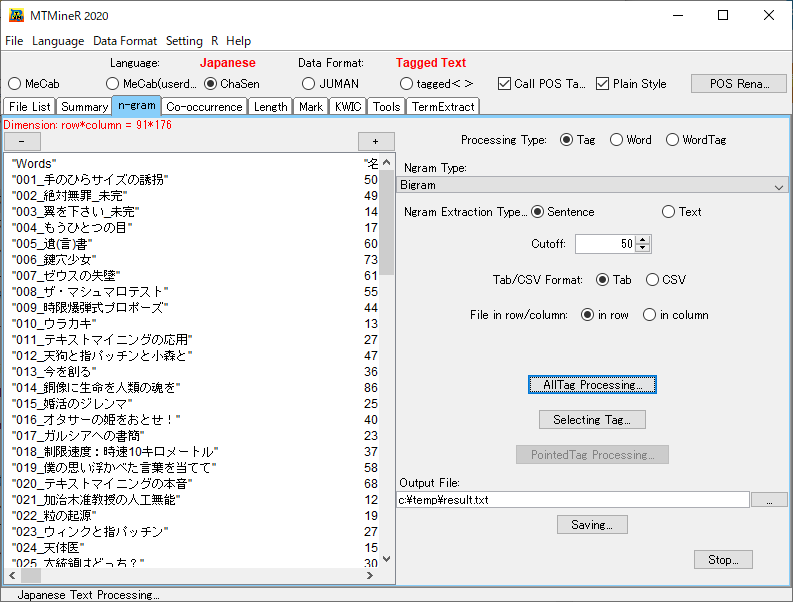
<n-gram>というタブを選び、下の参考画像のように設定します。なお、画像は<AllTag Processing>を押した後の画面です。

- <Processing Type>は<Tag>を選びます。
- <Ngram Type>は<Bigram>を選びます。
- <Ngram Extraction Type>は<Sentence>を選びます。
- <Cutoff>は50に設定します。小さい値にすると動作が重くなります。
- <Tab/CSV Format>や<File in row/column>は画像の設定で大丈夫です。
- 設定が完了したら<AllTag Processing>を押下します。
これは名詞や動詞などの品詞を出力するという意味です。
これは品詞の二つの組み合わせを意味します。例えば、名詞と助詞、助詞と動詞などです。
句点で区切られた文という意味です。
出力形式を変えるだけなので、結果に影響はありません。
R実行画面でデータを相対頻度に変換する
R実行画面を立ち上げ、まずはデータを相対頻度に変換します。
下の画面を参考にして下さい。

- メニューの<R>を選択し<Process Outputs In This Tab>を選びます。
- Run Rの画面の中央下の<Processing>を押します。
- Run R画面の上部にある<Select Data>で相対頻度のデータを選びます。
- Processing Sucessの画面は<OK>を押して閉じます。
Set Data Nameはデフォルトのtempのままで<OK>を押します。
Run R、R Console、OUTPUTの三つの画面が立ち上がります。
<Command>の<Proportion in Each Row>は、行の総和を基準とした相対頻度に変える、という意味です。
Data Nameをtempとした場合はtemp.traになっているはずです。
R実行画面で階層的クラスター分析を実行する
<Unspervised>のタブで<Hierachical Clustering>を選び、樹形図(デンドログラム)を描きます。
実行画面は下の画像の通りです。この状態で<OK>を押すと、樹形図が出力されます。

- <Unspervised>のタブで<Hierachical Clustering>を選びます。
- <Vriables>の下にあるボックスからデータを<Picked: 0>の下にボックスに移します。
- <Subset>の下にあるボックスからデータを<Picked: 0>の下にボックスに移します。
- <Methods>は<Ward.D2>を選びます。
- <Distance Measures>は<Jaccard dist>を選びます。
- 画面下の<OK>を押します。
丸い青い右向きの矢印を押すと、左から右へ移動します。
これも、丸い青い右向きの矢印を押すと、左から右へ移動します。
これは階層的クラスター分析に使用するデータを選択しています。
結果
下図のような樹形図が出力されます。
全てではありませんが、概ね、作者ごとにクラスターができあがっています。

この記事のまとめ
MTMineRを使った階層的クラスター分析のやり方をご紹介しました。
参考文献
・テキストマイニングによる筆者識別の正確性ならびに判定手続きの標準化
2.5文体的特徴で、品詞のbigramの記述があります。筆者識別力が高い文章の特徴として挙げられています。また、この論文はMTMineRを使って分析してます。